pyproximal.optimization.primal.ProximalGradient¶
- pyproximal.optimization.primal.ProximalGradient(proxf: ProxOperator, proxg: ProxOperator, x0: ndarray[tuple[Any, ...], dtype[_ScalarT]], epsg: float | ndarray[tuple[Any, ...], dtype[_ScalarT]] = 1.0, tau: float | None = None, backtracking: bool = False, beta: float = 0.5, eta: float = 1.0, niter: int = 10, niterback: int = 100, acceleration: str | None = None, tol: float | None = None, rtol: float | None = None, callback: Callable[[ndarray[tuple[Any, ...], dtype[_ScalarT]]], None] | None = None, show: bool = False, itershow: tuple[int, int, int] = (10, 10, 10)) ndarray[tuple[Any, ...], dtype[_ScalarT]][source]¶
Proximal gradient (optionally accelerated)
Solves the following minimization problem using (Accelerated) Proximal gradient algorithm:
\[\mathbf{x} = \argmin_\mathbf{x} f(\mathbf{x}) + \epsilon g(\mathbf{x})\]where \(f(\mathbf{x})\) is a smooth convex function with a uniquely defined gradient and \(g(\mathbf{x})\) is any convex function that has a known proximal operator.
- Parameters:
- proxf
pyproximal.ProxOperator Proximal operator of f function (must have
gradimplemented)- proxg
pyproximal.ProxOperator Proximal operator of g function
- x0
numpy.ndarray Initial vector
- epsg
floatornumpy.ndarray, optional Scaling factor of g function. Can be a scalar for iteration-independent scaling or a a 1d vector for iteration-dependent scaling
- tau
floatornumpy.ndarray, optional Positive scalar weight, which should satisfy the following condition to guarantees convergence: \(\tau \in (0, 1/L]\) where
Lis the Lipschitz constant of \(\nabla f\). Whentau=None, backtracking is used to adaptively estimate the best tau at each iteration. Finally, note that \(\tau\) can be chosen to be a vector when dealing with problems with multiple right-hand-sides- backtracking
bool, optional Force backtracking, even if
tauis not equal toNone. In this case the chosentauwill be used as the initial guess in the first step of backtracking- beta
float, optional Backtracking parameter (must be between 0 and 1)
- eta
float, optional Relaxation parameter (must be between 0 and 1, 0 excluded).
- niter
int, optional Number of iterations of iterative scheme
- niterback
int, optional Max number of iterations of backtracking
- acceleration
str, optional Acceleration (
None,vandenbergheorfista)- tol
float, optional Tolerance on change of objective function (used as stopping criterion). If
tol=None, run untilniteris reached or the other tolerance criterion is met- rtol
float, optional Relative tolerance on objective function wrt initial value. Stops the solver when the ratio of the current objective function to the initial objective function is below this value. If
rtol=None, run untilniteris reached or the other tolerance criterion is met- callback
callable, optional Function with signature (
callback(x)) to call after each iteration wherexis the current model vector- show
bool, optional Display iterations log
- itershow
tuple, optional Display set log for the first N1 steps, last N2 steps, and every N3 steps in between where N1, N2, N3 are the three element of the list.
- proxf
- Returns:
- x
numpy.ndarray Inverted model
- x
Notes
Examples using pyproximal.optimization.primal.ProximalGradient¶

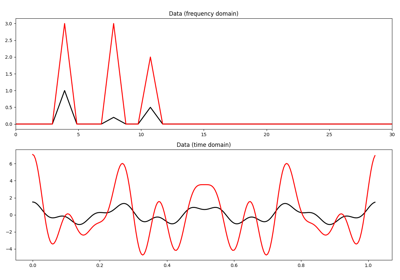
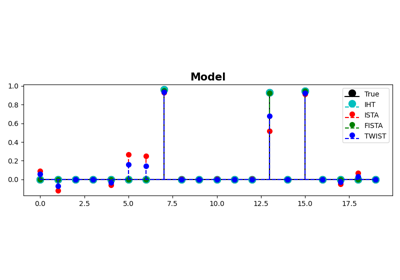
IHT, ISTA, FISTA, AA-ISTA, and TWIST for Compressive sensing